I outlined my whole plan here on my Patreon Campaign. You’ll see a new page on this site soon acknowledging supporters, and I’ll update you on the progress.
Whether you can give financially, or even if you just share the campaign with your data science friends, you are helping Becoming a Data Scientist podcast, the learning club, Data Sci Guide, Jobs for New Data Scientists, and all of my websites get off the ground! Thank you!!
Please fill out the survey and share it with your friends and followers on social media! The survey is a little long/detailed, but most of it is optional. I value your opinions! Thank you so much for participating!!
]]>At the end of each podcast episode, I’ll be “assigning” a “Learning Activity” for the Data Science Learning Club. So that is starting tomorrow, too! There won’t be anyone teaching the content, but we’ll be exploring it together for 1-2 weeks between podcast episodes (usually 2 weeks). I’ll post some resources to get everyone started and help out data science beginners, then we’ll each explore the activity on our own with whatever tools and techniques we choose, and we can post our results so we can all learn from one another. If anyone gets stuck, you can post a question to the forum and hopefully someone will be able to help you through it.
I just got the Data Science Learning Club forum set up today, and it’s at this URL: https://www.becomingadatascientist.com/learningclub
Go check it out, register so you can participate, read the Welcome thread, and introduce yourself in the Meet & Greet section! Then tomorrow, the first learning activity will launch and you can get started.
I’m so excited about launching this podcast and data science learning club, and hope this turns out to be a valuable experience for all of us! Keep an eye out on the blog for the podcast post, which should go up tomorrow!
Renee
]]>Data scientists are problem solvers at heart, and we love our data and our algorithms that sometimes seem to work like magic, so we may be inclined to try to solve these problems stemming from human bias by turning the decisions over to machines. Most people seem to believe that machines are less biased and more pure in their decision-making – that the data tells the truth, that the machines won’t discriminate.
Most people seem to believe that machines are less biased and more pure in their decision-making – that the data tells the truth, that the machines won’t discriminate.
However, we must remember that humans decide what data to collect and report (and whether to be honest in their data collection), what data to load into our models, how to manipulate that data, what tradeoffs we’re willing to accept, and how good is good enough for an algorithm to perform. Machines may not inherently discriminate, but humans ultimately tell the machines what to do, and then translate the results into information for other humans to use.
We aim to feed enough parameters into a model, and improve the algorithms enough, that we can tell who will pay back that loan, who will succeed in school, who will become a repeat offender, which company will make us money, which team will win the championship. If we just had more data, better processing systems, smarter analysts, smarter machines, we could predict the future.
I think Chris Anderson was right in his 2008 Wired article when he said “The new availability of huge amounts of data, along with the statistical tools to crunch these numbers, offers a whole new way of understanding the world,” but I think he was wrong when he said that petabyte-scale data “forces us to view data mathematically first and establish a context for it later,” and “With enough data, the numbers speak for themselves.” To me, context always matters. And numbers do not speak for themselves, we give them voice.
To me, context always matters. And numbers do not speak for themselves, we give them voice.
How aware are you of bias as you are building a data analysis, predictive model, visualization, or tool?
How complete, reliable, and representative is your dataset? Was your data collected by a smartphone app? Phone calls to listed numbers? Sensors? In-person surveying of whoever is out in the middle of the afternoon in the neighborhood your pollsters are covering, and agrees to stop and answer their questions?
Did you remove incomplete rows in your dataset to avoid problems your algorithm has with null values? Maybe the fact that the data was missing was meaningful; maybe the data was censored and not totally unknown. As Claudia Perlich warns, after cleaning your dataset, your data might have “lost its soul“.
Did you train your model on labeled data which already included some systematic bias?
It’s actually not surprising that a computer model built to evaluate resumes may eventually show the same biases as people do when you think about the details of how that model may have been built: Was the algorithm trained to evaluate applicants’ resumes against existing successful employees, who may have benefited from hiring biases themselves? Could there be a proxy for race or age or gender in the data even if you removed those variables? Maybe if you’ve never hired someone that grew up in the same zip code as a potential candidate, your model will dock them a few points for not being a close match to prior successful hires. Maybe people at your company have treated women poorly when they take a full maternity leave, so several have chosen to leave soon after they attempted to return, and the model therefore rates women of common childbearing age as having a higher probability of turnover, even though their sex and age are not (at least directly) the reason they left. In other words, our biases translate into machine biases when the data we feed the machine has biases built in, and we ask the machine to pattern-match.
We have to remember that Machine Learning effectively works by stereotyping. Our algorithms are often just creative ways to find things that are similar to other things. Sometimes, a process like this can reduce bias, if the system can identify predictors or combinations of predictors that may indicate a positive outcome, which a biased human may not consider if they’re hung up on another more obvious variable like race. However, as I mentioned before, we’re the ones training the system. We have to know where our data comes from, and how the ways we manipulate it can affect the results, and how the way we present those results can impact decisions that then impact people.
Data scientists, I challenge you. I challenge you to figure out how to make the systems you design as fair as possible.
Data scientists, I challenge you. I challenge you to figure out how to make the systems you design as fair as possible.
Sure, it makes sense to cluster people by basic demographic similarity in order to decide who to send which marketing message to so your company can sell more toys this Christmas than last. But when the stakes are serious – when the question is whether a person will get that job, or that loan, or that scholarship, or that kidney – I challenge you to do more than blindly run a big spreadsheet through a brute-force system that optimizes some standard performance measure, or lazily group people by zip code and income and elementary school grades without seeking information that may be better suited for the task at hand. Try to make sure your cost functions reflect the human costs of misclassification as well as the business costs. Seek to understand your data, and to understand as much as possible how the decisions you make while building your model are affecting the outcome. Check to see how your model performs on a subset of your data that represents historically disadvantaged people. Speak up when you see your results, your expertise, your model being used to create an unfair system.
As data scientists, even though we know that systems we build can do a lot of good, we also know they can do a lot of harm. As data scientists, we know there are outliers. We know there are misclassifications. We know there are people and families and communities behind the rows in our dataframes.
I challenge you, Data Scientists, to think about the people in your dataset, and to take steps necessary to make the systems you design as unbiased and fair as possible. I challenge you to remain the human in the loop.
The links throughout the article provide examples and references related to what is being discussed in each section. I encourage you to go back and click on them. Below are additional links with information that can help you identify and reduce biases in your analyses and models.
The GigaOm article “Careful: Your big data analytics may be polluted by data scientist bias” discusses some “bias-quelling tactics”
“Data Science: What You Already Know Can Hurt You” suggests solutions for avoiding “The Einstellung Effect”
Part I of the book Applied Predictive Modeling includes discussions of the modeling process and explains how each type of data manipluation during pre-processing can affect model outcome
This paper from the NIH outlines some biases that occur during clinical research and how to avoid them: “Identifying and Avoiding Bias in Research”
The study “Bias arising from missing data in predictive models” uses Monte Carlo simulation to determine how different methods of handling missing data affect odds-ratio estimates and model performance
Use these wikipedia articles to learn about Accuracy and Precision and Precision and Recall
A study in Clinical Chemistry examines “Bias in Sensitivity and Specificity Caused by Data-Driven Selection of Optimal Cutoff Values: Mechanisms, Magnitude, and Solutions”
More resources from a workshop on fairness, accountability, and transparency in machine learning
Edit: After listening to the SciFri episode I linked to in the comments, I found this paper “Certifying and removing disparate impact” about identifying and reducing bias in machine learning algorithms.
Edit 11/23: Carina Zona suggested that her talk “Consequences of an Insightful Algorithm” might be a good reference to include here. I agree!

(P.S. Sometimes the problem with turning a decision over to machines is that the machines can’t discriminate enough!)
Do you have a story related to data science and bias? Do you have additional links that would help us learn more? Please share in the comments!
]]>I had an idea today that would take it a step further. Imagine how book clubs work where you pick a book, go off and read it, then gather occasionally to discuss and record your thoughts. Except instead of a book club, it’s a data science learning club!
I’m imagining picking a topic/project, finding resources showing how to do it, and introducing it to the club at the end of a podcast episode. Then, everyone that wants to participate in learning how to do that particular thing will go off for maybe 2 weeks, work on it and learn what they can, ask questions to each other in a common area like a blog post comment thread, create things and post them to a shared space, then at the end of the period post comments about what they learned and how it went. People could write blog posts about their projects and I would collect those and link to all of them from the original post. Anyone that already knows how to do it could help answer questions if they wanted to participate, too. I might invite some of the participants to talk about their learning experience on a follow-up episode, then the notes and results would be posted for future learners to find.
I think learning together would be fun and valuable, and this type of experience would fall somewhere between learning on your own and taking a class. It would include the pros of learning on your own and exploring, while offsetting some of the cons of going at it alone. It would be a significant time commitment on my part, so I want to make sure other people would join in before I commit. What do you think? Would you join a “data science learning club” and participate in something like this and find it valuable? It’s kind of like the Summer of Data Science, but we’d be learning the same things simultaneously and sharing our results. No one would be “teaching” the group necessarily, but we’d share resources and answer each other’s questions based on what we did individually.
Let me know in the comments or on twitter if you would find this valuable and if you want me to lead it!
]]>———————–
A few things I should say first…. I think “data science” can be replaced by just about any other topic, but especially science & tech topics, so please keep that in mind as you read this. I follow a bunch of scientists on my “regular” personal twitter account @paix120, and I sense the same things going on in their communities as I’m about to outline for data science.
Another thing I want to mention is that I’ve had other “topical” twitter accounts. I created one called @womenwithdroids when I started a blog of the same name, and I was amazed at how many awesome women I met that were building android apps, wanted to learn more about how to use their android phones (which at the time were being marketed as a “manly” alternative to the “cutesy” iPhone), and wanted to join a community of women talking about android phones and apps. At the time, I had created a separate account because I saw it as a “business” account for my blog, but I realized that there was a lot of value in separating that from my personal account. I’ll go into that below. Now that you know a little background, let’s dive into how you can use twitter to learn just about anything.
———————–
I have explained to people I meet in person how much I gain from Twitter, and they often look at me like I’m a little nutty. I have heard a few recurring comments from them that I see as misconceptions:
- “I started using Twitter and was overwhelmed. I couldn’t keep up with my timeline.”
My answer to that is that first, you’re not supposed to “keep up” with your Twitter timeline. I don’t use Facebook, but I get the impression that people that do will scroll back through every post that happened since the last time they visited, to make sure they don’t miss any important info from their friends. Twitter is not like that.
On Twitter, you can jump on when you need a 5-minute break from work, read a few tweets, mark some longer stories to read later or go read an article or two now, and then get right back to work. People that use twitter won’t get mad if you miss one of their tweets. If something resonates with a lot of people, it will be retweeted and you will probably see it later. If not, it’s not a big deal. You see what you see when you’re online, and don’t worry about what you may have missed, it will just stress you out.
Think of Twitter like the news. You may want to see if anything has just happened, what’s at the “top of the news”, or what people are talking about that happened recently. If there is a big news story, it will likely still be visible when you visit later. It would be stressful to try to keep up with every news article that’s published at any time.
I just scroll back a half hour or so and scroll up until I’m ready to do something else. If I’m looking for tweets about a specific topic, I do a search and see what the top tweets are for it. You can narrow down the search results to “People You Follow” if you only want to see what people you are connected with are saying about the topic.
- “I started using Twitter and it was just a bunch of junk I didn’t care about.”
Twitter has an onboarding problem. The problem used to be that when you started a new account, you weren’t following anyone, then people would feel lost and not know how to find interesting accounts to follow. Then they started suggesting interesting accounts. Now, the onboarding process shows you a whole bunch of “brand” accounts to follow (whether those are celebrities or companies, they are usually accounts generated to gain followers or money), then they also try to get you to import your email contacts and follow all of them. I don’t know about you, but I don’t care much about what celebrities have to say, and many of my email contacts are people that I had a short business exchange with years ago and have no interest in keeping up with now. It’s no wonder people start with an uninteresting and overwhelming timeline.
My recommendation is that if there is someone in your timeline that frequently annoys you or tweets boring stuff, unfollow them. That’s just clutter. If you see a friend retweet something from someone you don’t follow that is interesting, click on that person’s profile, read a few tweets and see if they are tweeting other things that interest you, and if so, follow them. Constantly tailor your timeline to work for you.
Another important suggestion is to use twitter lists. If there are certain people that you really do want to keep up with (like personal friends, or a small group of accounts on a very specific topic), put them in a list. You can also follow them in your normal timeline, but you don’t have to. When you click over to your list, you will see only tweets by those accounts. One example of how I use a list on my personal account is my “Harrisonburg businesses” list. I don’t frequently care about whether a local restaurant is having a special, or if there’s a cultural event going on at our local university. However, when I’m looking for something to do one night, I can click over to that list and see what the local businesses are tweeting about today. Are there any cool bands playing in town? A special at a local hangout? I follow very few of those 160+ accounts in my regular timeline, but now I have a collection of them in one place when I do want to scroll back through 24 hours of tweets to find something specific.
- “Social Media is a time suck for me, and I don’t want to add any more social feeds to my life to waste time on”
OK, I can see this. It is easy to get sucked in and spend a lot of time on social media. To me, this is just a reason to optimize your account so it’s beneficial to you. If you’re just reading celebrity gossip and trending topics, are you improving your life? However, if you have a goal to become a data scientist, and you follow accounts that are actually educating you, is it so bad to spend some time “sucked into” a feed that is actually getting you closer to your goal in your “free time” and keeping you up to date on the latest topics that a colleague or future employer may expect you to know about?
———————–
Now that I’ve explained some misconceptions about Twitter, I want to explain why I have a separate account for “Data Science Renee”. I have had my personal account on Twitter since 2008. I have only really been into data science since late 2013. I have a “network” of people that I chat with about a variety of topics on my personal account, including political topics and random things that catch my attention. Here are my main reasons for starting a separate account for @becomingdatasci:
-
I personally wanted to separate the topic out. I wanted to go “all in” on data science, and have an account where I ONLY follow people that talk about data science, even people I wouldn’t follow in my normal timeline. I could have done this with a list, but I wanted to take it further than that.
-
I also wanted to be able to tweet like crazy about data science, and not feel like I had to hold back in order to avoid overwhelming my existing followers with a flood of tweets on a new topic. They might unfollow me if I started tweeting 20 times a day about data science when I had rarely mentioned it before, and my new interest might far outweigh my tweets on other topics I’m interested in. I didn’t want to lose that existing network.
-
The opposite is also true. I wanted to be able to connect this new account to my blog, and use it to make work connections, without worrying about including personal political views and tweets about gardening and cute animals in that feed! I also would know that people that follow this account are following it because of data science. I check out my followers on this account more often than I do on my personal account, because they’re more likely to share this particular interest with me.
-
I know I’m good at curating interesting articles about a topic, and I wanted this account to be considered a “go to” account that others could recommend to their friends interested in learning about data science, without worrying what else I might be tweeting about. I decided to become a sort of “learning data science channel”.
———————–
So you see why I have separated this account from my existing personal Twitter account, and how I have tailored it to work for me. But what does that mean? What have I actually gained from this twitter account?
-
I have learned a LOT that I wouldn’t otherwise know about data science. There are terms that I wouldn’t have known to Google that some of the people I follow tweet about and link to articles, academic publications, and tutorials about. There is a constant flow of interesting new information coming out of the data science “industry” so I can keep up with what is being talked about right now and what is considered “state of the art” and exciting to other data scientists. It’s like being able to walk around and listen in on lunch tables at a data science conference. Everyone is talking about something slightly different, but all in the general topic of data science, and each person is honing in on what is interesting or exciting to them within this realm.
-
I have made connections that I wouldn’t have made otherwise. I don’t have a lot of time or money to constantly travel to data science conferences and meet people in person. I live in a small town and there aren’t a lot of other people talking about data science here (yet). Twitter has given me a way to personally connect with other data scientists. I have connected with some that don’t live far from me, after all! I have connected with many that live in other countries that I likely wouldn’t even meet at a conference. These connections have cheered me on in my learning, connected me to resources, and more!
-
I have become a “face” of a person learning data science. At once conference I did attend, I was recognized as “Data Science Renee”! I have been asked to be interviewed on podcasts and blogs (some of those should be coming up soon), offered contract work, and offered free admission to a conference I unfortunately couldn’t go to, but was excited to be considered for. “Famous” people in the industry are now coming to me to work with them in some way. New learners seem to look to me as a resource and guide, and want to see how I learned what I know, and how I have struggled, so they can compare that to their own experiences.
-
I have found many other women working in data science. When I was first learning about data science, all of the “who’s who” lists of people to follow, people that were interviewed for books or other resources, and the “faces” of data science were often white or asian men, with maybe one woman or minority included in the group. (This is typical of the tech industry.) However, as I made more and more connections, and started to seek out women and other minorities in the industry, I have been able to connect with them and learn from them and hopefully amplify their voices. I now have a twitter list with almost 450 women that work in data science or statistics, and now that list can be a resource for other women looking for role models like them in the industry!
-
I have learned some specific data science tools and techniques. I regularly see great tutorials on twitter, via blog posts or videos or github links, that show me how to do something I have wanted to learn how to do. These would often be hard to find by searching, but come right to me in my twitter feed where I can bookmark them for later learning sessions.
-
People on twitter have reached out to help me solve problems when I’m stuck. I have received tweets from people that built python packages I was using, people that had resources that could help me, or just people with general advice and feedback! If I’m clear about what I’m doing and where I’m stuck, I now have a strong enough follower base that I will almost always get a helpful answer!
-
Not only do I find out about resources I wouldn’t otherwise have, but I see opinions of others on existing resources. A conversation on twitter about being overwhelmed by the vast amount of things there are to learn in the broad topic of “data science” helped inspire me to bring an idea I had been having to life. I have taken a course online that got really difficult at about the 5th lesson. I didn’t know whether it was just me and I had hit a roadblock, or if a lot of people found that course difficult and I just needed some outside resources to continue with it. I also often don’t know where to start in my long list of bookmarked “things to learn”. But seeing what people tweet about, and how others have learned, really is helping me on my learning journey. You can read about my new website DataSciGuide here. I’m hoping the ratings (and eventually learning guides and a recommender system) there will help others avoid “data science learning overwhelm”. (P.S. I’m now in the phase where I need reviews on the items I’ve posted, so please go rate some things!)
———————–
Hopefully this post has helped you understand how to use Twitter to join a community and learn something you have been wanting to learn! You can really gain a lot from it if you optimize its benefit to you like I have.
I know the question now will be, “so who are the best people to follow on twitter for data science?,” and I’m hesitant to answer that for you since there are so many people out there, some with specific topics that would be better for you personally than what I would recommend. For instance, maybe you are especially interested in learning data science for sports analytics, which is a specific topic I don’t follow many people on.
If you follow me on @becomingdatasci and see who I retweet, you’ll find people that are sharing resources that I think are beneficial, so you can start there. You can’t go by my twitter favorites since I use those as bookmarks and haven’t read many of them yet. You could look through people I follow, but there are a lot of them, and they’re not ranked in a helpful way. You can also follow the list of data science women I mentioned above.
Others that are often good to start with are people with data science blogs, since they’re usually purposely writing to educate others. Here’s a large list of data science blogs that includes the twitter handle of the author or blog where applicable, and is sorted into categories. Check it out! https://blog.rjmetrics.com/2015/09/30/the-ultimate-guide-to-data-science-blogs-150-and-counting/
———————–
So to recap:
Tailor your twitter timeline frequently. Unfollow those that annoy or bore you, and follow new accounts on topics you want to know more about.
If you seriously want to hone in on one topic, or to become a “channel” for a topic, create a separate account for it
Use twitter lists to create small lists of people you especially want to keep up with, or sub-specialty topics you occasionally want to dive into. You can follow accounts in lists that you might not otherwise follow in your timeline.
Actually connect with other people. Find people like you that can be role models for your learning. Ask them questions. Help others out when they ask questions on a topic you know more about. Join the community and the conversation.
Have fun and don’t get overwhelmed! Use others’ opinions and recommendations to carve out your learning path.
Comment below if you have any questions about using twitter to help learn data science!
]]>That site isn’t open for comments yet, so I’m directing people to leave feedback here.
If you haven’t kept up with the development of DataSciGuide, here are a few things to read:
Let me know if you want an account to post some reviews while I test things out! (I’ll even post content that you want to review, just for you.)
Also, tell me any thoughts you have about the site in the comment form below! (or tweet me!)
]]>[Spoiler Alerts – but you probably already know much of the story, and the movie is still good even if you know the historical outcome.]
I thought a moment like this may be coming when Alan Turing was first applying to work at Bletchley Park, and Denniston can’t believe he’s applying to be a Nazi codebreaker without even knowing how to speak German. Alan emphasizes that he is masterful at games and solving puzzles, and that the Nazi Enigma machine is a puzzle he wants to solve. He starts designing and building a machine that will theoretically be able to decode the Nazi radio transmissions, but the decoder settings change every day at 12am, so the machine must solve for the settings before the stroke of midnight every day in order for the day’s messages to be decoded in time to be useful and not interfere with the next day’s decoding process. Turing can’t prove his machine will work, simply because it is simply taking too long to solve the daily puzzle. In the meantime, people are dying in the war, and the Nazis are going on transmitting their messages over normal radio waves believing the code is “unbreakable”.
[More specific plot spoiler in the 2 paragraphs below]
The moment I’m referring to is when Alan hears a woman explaining that the German man whose messages she is assigned to translate always starts his messages off with “Cilla”, who she assumes is the transmitter’s girlfriend. This triggers Alan to realize there could be repeated messages that would drastically narrow down the number of decryption keys because you could specify that there was always a word or phrase that could be expected in the messages. They realized that there was a 6am weather report transmitted daily, and that every message ended in “Heil Hitler”, so they set the machine so it could focus its search on finding the words “weather”, “heil”, and “Hitler” in the 6am message every day. This solved the puzzle, as the machine was then able to quickly decode the messages from a narrower set of possible solutions instead of running all day without finding one.
So, Alan Turing (at least in the movie version) had been focusing on a random set of hundreds of millions of possible solutions, which his machine could solve faster than humans, and trying to tune the design of his machine to find the solution faster. The hint that ended up leading to the solution involved bringing the human thought process back into it – if there was something the messages said frequently, because they were written by humans, and humans follow certain communication and linguistic patterns, that could be exploited to narrow down the range of solutions.
[/end specific plot spoiler]
This got me thinking about machine learning and data science in general. A frequent Kaggle competition winning strategy is to quickly iterate through a multitude of algorithms and optimize for the evaluation metric, or focus on stacking thousands of models. [Here are several interviews with Kaggle winners.] Some of the winners do mention needing to study up on the field to gain some domain expertise, and the Quora answer here focuses on data understanding a preparation, but many teams appear to take a brute-force-type approach to building their models and writing programs to iterate through each combination of algorithms to maximize the area under the curve or whatever measure that particular competition is scored on.
I don’t want to do that type of brute-force data science. I’ll leave that up to the competitive types that enjoy quickly iterating through as many solutions as possible, and building systems to help them do this faster, and have a focus on winning vs understanding. Of course there is a place for that type of approach, and it is very valuable in solving some problems, but it’s not attractive to me. It’s too robotic.
However, there are many areas (like my day-job, university/non-profit fundraising), where knowing your specific community, what types of data you’re collecting, where it’s from, how trustworthy it is, will have a large impact on what fields you decide to include in your model and of course how you interpret the output. These are areas where we’re talking about data with a lot of variety, but not necessarily a lot of volume (at least not on the scale of something like credit card processing and fraud detection), and where I would think domain expertise is more valuable than fast model optimization. It is also vital to be able to explain how to be able to use the output of a given model. It is more of a consulting role than a mathematical/programming one.
I think that’s where I’m headed in my data science learning. I am aiming to learn how to use models to inform decision-making, how to choose the best data to put into a model, how to choose which type of model to use, and how to watch out for things like covariance and other confounding effects. Then, when you get a result, how to know whether to trust the result, how to explain it to non-technical managers, and how to best implement what was learned in order to have a positive impact on real-world outcomes. It is more of a creative iterative cycle than a machine/optimization iterative cycle.
Like in Imitation Game, understanding human behavior and communication can be the “big hint” that informs a technical solution, and optimizes its performance beyond what a better-tuned piece of hardware or more efficient code could do. It seems to me (and I have heard others saying) that understanding people and business is more than just a piece of the “data science venn diagram”, it’s really the key to success in this field. (And also a good reason to have diverse data science teams.)
I’m curious about how those of you that work as data scientists see these various aspects of data science, and how much of your work involves creative and “human” skills vs the “hard skills” of math and computer science. I would think it varies depending on industry and the type of problem you’re trying to solve, but I am interested in your personal experience. Please comment below to share your experiences!
]]>
My main motivation is that I keep hearing people say (and sometimes feel myself) that learning to becoming a data scientist on your own using online resources is totally overwhelming: there are so many different possible topics to dive into, few really good guides, lots of impostor-syndrome-inducing posts by people you follow that make you feel like they’re so far ahead of where you are and you’ll *never* get there…. but there’s so much great data science learning content online for everyone from beginners to experienced data scientists!
We need a better way to navigate it.
Hence my new website: “Data Sci Guide”. It will eventually have a personalized recommender system and structured learning guides and all kinds of other features to help you find the resources to go from where you are to where you want to be, but for now it’s “just” a directory / content rating site. And it’s not ready for you to interact with yet, but it’s getting there, and I’ll need your help fleshing it all out soon.
So go take a look! Then come back here to give me feedback and suggestions, because you have to be registered to comment there and I didn’t turn on new user registration yet.
OK go now. Don’t forget to come back!
>>>> DATA SCI GUIDE.COM <<<
So…. what did you think? What do you think of the overall idea and plans? What should I be sure to remember to include? Tell me below!
]]>
I posted this picture on Twitter:

and got some interesting responses:
@BecomingDataSci I'd include familiarity with business process in one of those columns. Can't analyze in a vacuum,.
— Karen Clark (@clarkkaren) July 17, 2015
@BecomingDataSci @aflyax You've got analytical thinking & problem solving. Maybe add "adaptable to a variety of environments" as generic?
— Karen Clark (@clarkkaren) July 20, 2015
@barbarafenton i mentioned that as a misconception! i spend a lot more time communicating than most people think
— Data Science Renee (@BecomingDataSci) July 17, 2015
@DataSkeptic yes i think that's important, but you can get an entry level job w/just basic charting skills. was trying to keep to minimum.
— Data Science Renee (@BecomingDataSci) July 17, 2015
@BecomingDataSci so e.g. "SQL" could be "data manipulation skills (e.g. SQL)" – don't get hung up on a specific tool to to the job! 2/2
— Martin Monkman (@monkmanmh) July 17, 2015
@BecomingDataSci This is great! My ready-fire-aim data science side says to add "asking forgiveness is easier than permission" to traits :P
— Shannon Quinn (@SpectralFilter) July 17, 2015
@BecomingDataSci I'd add : autodidact
— craig pfeifer (@aCraigPfeifer) July 17, 2015
What do you think?
I’ll revisit this topic later, and I’ll also post about the conference I’m attending (APRA Data Analytics Symposium) when I have a chance to summarize. For the moment, heading back to the sessions!
]]>I had a thought while daydreaming, and tweeted this, thinking a few people might think it was fun and respond:
I'm planning to do a lot of data science learning this summer. Anyone else? Maybe we shld start a hashtag #SoDS "Summer of Data Science" :)
— Data Science Renee (@BecomingDataSci) May 14, 2015
…and as you can see by the RT and Favorite count, it kind of took on a life of its own!
I thought of a variation
…or maybe more fun #SODAS "Summer of Data Science". like a cool, refreshing beverage. & we'll hand off to So Hemisphere ppl in the fall :)
— Data Science Renee (@BecomingDataSci) May 14, 2015
and so did some other people
@BecomingDataSci It could be #SoDaS (just add the little "a" in there for D"a"ta…)
— Nicole Radziwill (@nicoleradziwill) May 14, 2015
@BecomingDataSci #DSS15 Data Science Summer 2015
— BigMikeInAustin (@BigMikeInAustin) May 14, 2015
In the end, it looks like #SoDS won…. and got a whole lot of support because of a RT by @dpatil! Thanks to him, this is what my notifications started to look like:
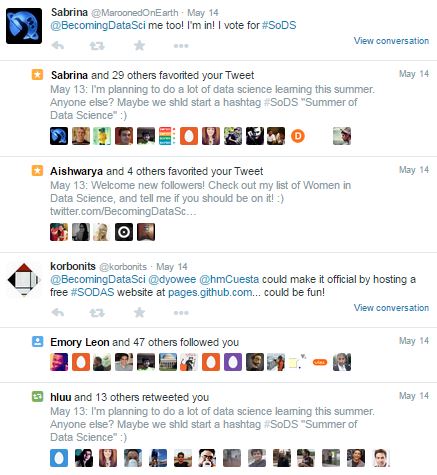
Too bad I was supposed to be working on writing up something for work…. that didn’t get done that night! I came back later and was really surprised by the response!
I was excited by all of the new followers, and especially happy that some people appeared to have been inspired by the hashtag to do some data science learning of their own!
@BecomingDataSci @seinecle and is there something like "data science for über-beginners"? =D
— Lexane Sirac (@lexanesirac) May 14, 2015
2 minutes later…
@BecomingDataSci @seinecle @clarecorthell thank you so much! I'll make sure to take part in #SoDS then!
— Lexane Sirac (@lexanesirac) May 14, 2015
So it seems I started something and now I need to follow up! I’m going to tag my summer learning projects on here with the “#SoDS 2015” post category, and tweet about them (of course!) using the #SoDS hashtag on twitter. Will you join me? :)
Here’s to an awesome Summer of Data Science! Now I’m going to try to go respond to all of your tweets!
(P.S. the hashtag just started being used by some Dutch foodies, but we’ll overwhelm that version with our data science tweets pretty soon!)
P.P.S. we even have a unicorn joining us this summer!
@BecomingDataSci @DataSkeptic count me in! #SoDS #becomingaunicorn
— Data Science Unicorn (@DataScienceUni) May 14, 2015
]]>I’ve been listening to a lot of data science podcasts lately, and I think there’s room for another one. And I want to make it. I’m thinking that I would interview people about how they became a data scientist: what their educational background is, what resources they use to keep learning on their own, what tools they use, how they interviewed for data science jobs, what they do now, etc…. maybe it would be a Google Hangout, then I could post both the video and audio-only versions.
I tweeted about this idea and got some good feedback about it. What do you think? Are you interested?
Which data scientists would you most want to learn more about?
P.S. I’m reading the book Data Scientists at Work by Sebastian Gutierrez (slowly, around grad class work), and I’m really enjoying it. If you want to read interviews of data scientists where they detail what they do and why they’re passionate about it, check it out!
I’ve been so busy with projects lately (for work, class, personal), that I haven’t been able to do as many data science learning projects as I’ve wanted to, but I have been reading up, and I wanted to share some articles I recently found interesting with you!
The first is “Crushed It! Landing a data science job” by Erin Shellman, which I received via the Get a Data Science Job newsletter.
Erin talks about her recent experience with various types of Data Science interviews, which ended in her being hired at Amazon Web Services. She gives great advice about how to prepare for these interviews, as well as a ton of great resources for learning. I’ve definitely bookmarked several of her book and course recommendations.
Advice from Erin Shellman: “Take the time to be sure that you can explain core concepts in your own words. Screening questions are commonly phrased like this: “how would you explain to an engineer how to interpret a p-value?” Explain it to an engineer, someone who, presumably, isn’t a statistician and might not be used to that language. You don’t want it to be the first time you’ve had to rephrase basic definitions like that. Also, don’t underestimate what nerves can do to your ability to recall information, even stuff you really thought you understood.”
Check out her full post here: http://www.erinshellman.com/crushed-it-landing-a-data-science-job/
The second article interested me, because about a year ago when I heard about UrtheCast, I was brainstorming data-sciencey projects that could be done with satellite image data, and thought it would be so cool to learn how to identify and track large mammals like elephants and whales from space. Well, guess what? It’s already being done!
If you think you like elephants and whales now, just wait until you see them FROM SPACE http://t.co/bz6ND5wKkC
— Parker Higgins (@xor) March 28, 2015
The article Parker Higgins is referring to in the tweet above is from The Atlantic, and details how analysts at DigitalGlobe were able to identify elephants in the Democratic Republic of Congo and help protect them from poachers. A different team at DigitalGlobe used an algorithm to spot whales surfacing near the coast of Argentina from ocean imagery – how cool!
At the Girl Develop It! meetup where I talked about data science, some of the participants and I had questions about using geospatial/GIS data for various types of analysis, and decided to schedule a new meetup. My husband knows some professors that do research in this area, and there were a couple people at the meetup that also had some experience with satellite imagery, so I’m going to plan a follow-up meetup to discuss that topic in more depth. Keep an eye on this blog for any announcements about that. I’m thinking maybe late May?
I always tweet interesting articles I read, so for more, follow me on Twitter!
]]>So, here’s a bit about what I’ve been up to data-science-wise:
- I’m in a grad class called Stochastic Models and we’re learning about Markov Chains right now. Fascinating stuff! Here’s a cool site that visually shows some Markov Chain concepts.
- My other grad class is Intro to Systems Engineering. (Yeah, because of the courses offered online, I’m taking the intro class in my second-to-last semester!) We just did a neat project in that class that involved coming up with a strategy and participating in a baseball draft, so I’ll come back later and write about that in more detail.
- I’m almost at the end of Udacity’s Cloudera Hadoop course. I am really enjoying learning about MapReduce, and will definitely write up a review of the class when I’m done. The biggest frustrations I’ve had so far haven’t involved the Hadoop concepts, but using the VM they provide has been frustrating! All I have left on that is the final project, so soon i’ll be able to cross that one off my goals list.
- Soon, I need to come up with a final project for my Systems Engineering Masters degree. I’m definitely doing something data science related, and will update when that plan is finalized.
- I’ve been telling more people about my data science plans, and have had more people asking me about data science and the learning process. I may be giving a talk to my alma mater’s IEEE Computer Society club meeting soon about “What is data science?”, so that will be fun!
Are you “becoming a data scientist”, too? What projects are you in the middle of right now?
]]>I think the course would be good for people that have had at least an introductory programming course in the past. I didn’t have much trouble with the tasks (though a few were pretty tricky), but I have programming experience (and taught myself some advanced Python outside of the course for my Machine Learning class) and can imagine that someone that had never programmed before and was unfamiliar with basic concepts might get totally stuck at points in the course. I think they need 2 levels of “hints” per topic so that if you just need hints on the most common difficult things that trip people up, you click it once and get the hints they show now. But if you’re truly stuck and need to be walked through it, they should have more in-depth hints for true beginners.
The site estimates it will take you 13 hours to complete the course. I don’t know how much time I spent on it total, since it was broken up over months. It took me about an hour to finish the final 10% of the course, covering classes, inheritance, overrides, file input/output and reviews, then also going back and figuring out where the final 1% was that it said I hadn’t completed (apparently I skipped some topic mid-course accidentally) so I could get the 100% topic complete status.
The topics covered are:
- Python Syntax
- Strings and Console Output
- Conditionals and Control Flow
- Functions
- Lists & Dictionaries
- Loops
- Iteration over Data Structures
- Bitwise Operators
- Classes
- File Input & Output
I thought this was a good set of topics for an intro course. If they dropped anything, I think Bitwise Operators was a “bit” unnecessary for beginners. I liked the projects they included to test out the skills you learned, like writing a program as if you are a teacher and need to calculate statistics on your class’ test scores.
Overall, I think Codecademy did a good job with this course, and I would point other programmers that want to quickly get up to speed on Python to take this course. I would also point beginners to the course, but with a warning that there are tricky spots they may need outside resources to get through.
]]>Now I can cross that one off the list: Updated Goals
]]>Very good analysis and you showed great potential to become a good researcher!
Comments:
1. when you code your categories features, 1 of k coding is a good choice. Did you apply this method to all categories features?2. Some time, normorlize features will make a huge difference. One way to do this is to comput the z-score for features before you train a model on the data.
3. In terms of machine learning application, your analysis is good. If you try to find a social study expert to collobrate with you, I believe your findings can be published on high impacting journals.
4. In order to publish your work, you will need to do some research to found what have been done in this field.
This is especially encouraging since I want to become a data scientist, so hearing positive feedback like this, even encouraging me to publish after having only taken one semester of Machine Learning, feels great!
So, I will take time this summer to do more research and learning and expand on this project (since it was a rush to complete enough to turn in on time in this class but there’s a lot more I want to do with it), and I will collaborate with some people at the university where I work to further distill the results and see if we can apply them to segment out some potential first-time donors for next fiscal year.
This is fun!
]]>In that post, Paco Nathan, “a data science expert with 25+ years of industry experience”, is interviewed about Data Science as a career path, and gives his opinions on whether it is a “sexy” career, as well as sharing advice for those people (like me) considering a career in the field.
Though I think Paco Nathan makes some very good points throughout the interview, such as “be careful of where you go to work”, “learn to leverage the evolving Py data stack”, “learn to lead an interdisciplinary team”, and “find mentors”, my overall reaction to the interview was somewhat negative and I almost stopped reading before I got to the good advice.
I think my reaction mostly stems from the excerpt below, at the beginning of the interview:
Anmol Rajpurohit: Data Scientist has been termed as the sexiest job of 21st century. Do you agree? What advice would you give to people thinking of a long career in Data Science?
Paco Nathan: I don’t agree. Not many people have the breadth of skills to perform the role, nor the patience that is absolutely needed to acquire those skills, nor the desire to get there.
As a self test:
- prepare an analysis and visualization of an unknown data set, while impatient stakeholders watch over your shoulder and ask pointed questions; be prepared to make quantitative arguments about the confidence of the results
- describe “loss function” and “regularization term” each in 25 words or less, with a compare/contrast of several examples, and show how to structure a range of tradeoffs for model transparency, predictive power, and resource requirements
- pitch a reorg proposal to an executive staff session which implies firing some ranking people
- interview 34 different departments that are hostile to your project, to tease out the metadata for datasets that they’ve been reluctant to release
- build, test, and deploy a mission-critical app with realtime SLAs, efficiently across a 1000+ node cluster
- troubleshoot intermittent bugs in somebody else’s code which is at least 2000 lines long, without their assistance
- leverage ensemble approaches to enhance a predictive model that you’re working on
- work on a deadline in paired programming with people from 34 different fields completely disjoint from the work that you’ve done
If one doesn’t feel absolutely comfortable performing each of those listed above, right now, then my advice is to avoid “Data Science” as a career.
It’s that last sentence that is really bothering me. It’s unnecessarily discouraging.
It seems to me that this list, and especially the admonition that if you don’t feel *absolutely* comfortable performing all of these tasks *right now*, don’t even try to become a data scientist is a scare tactic and carries some of an “I survived it, but I doubt you can” attitude.
When I mentioned my negative reaction to the article on Twitter, Paco thanked me for my feedback, and asked whether I would consider it discouraging to give advice that if you’re in HR, you’d be firing people, or that if you plan to become an entrepreneur, there’s a high chance of failure.
curious: if one advised about HR ("you'll fire people") or about founding firms ("50% fail"), are those discouraging? @paix120 @dtunkelang
— paco nathan (@pacoid) April 1, 2014
No, I don’t think it’s overly negative to give people “reality checks” that may counter the popular culture version of what a particular job entails. I don’t doubt that someone pursuing a data science career will come across one or more of the situations he mentioned in the interview in their lifetime. However, how often do these occur? Is it a sure thing you’ll have a negative experience? Do these situations appear in every variation of a “data scientist” job? Are they more likely to happen if you join a company of a particular size or culture? Do you really have to be comfortable doing those things before even deciding to pursue data science? (Do you have to be comfortable running a marathon before you start training for one?)
Giving the advice quoted above is like saying “I’ve been running marathons for 25 years. Before you start training, give yourself this self test: Are you comfortable with recovering from a hamstring injury right now? Because hamstring injuries are common among marathon runners. I injured mine and it was excruciating” in response to someone that mentions to you that it’s their dream to one day run a marathon. Advising that it’s going to be a difficult path forward, with the possibility of an injury or negative experience along the way, and some tips for avoiding the pitfalls is enough. You don’t have to advise them not to try because training for a marathon is not as glamorous as they might first believe.
Should I, as someone that is a database designer, SQL developer, and Data Analyst that has run my own business, worked a data analyst at an internationally-known educational/retail business, developed analytical sql reports at a major university, and am halfway through a systems engineering master’s degree at a top university, “avoid data science as a career” because I wouldn’t feel comfortable “building, testing, and deploying a mission-critical app with realtime SLAs, efficiently across a 1000+ node cluster” “right now”? I don’t think so.
Now, maybe, as Daniel Tunkelang suggested, Paco Nathan is trying to “counter the proliferation of be-a-data-scientist-quick” programs.
@paix120 @BecomingDataSci I agree that @pacoid is overcompensating a bit to counter the proliferation of be-a-data-scientist-quick programs.
— Daniel Tunkelang (@dtunkelang) April 1, 2014
I can understand that point of view, and it seems like good advice to tell someone that if you’re going to become a data scientist, you shouldn’t expect it to come easy or be a quick process, and once you get hired, you are going to be up against a lot of misconceptions while having to deal with a lot of different types of people and power structures and challenging projects that aren’t as “sexy” as you might have first expected.
But is that a reason not to try? Another thought: if you fall short of becoming the “unicorn” data scientist that is a true expert in computer science, statistics, business, and has domain expertise to boot, have you failed? Or could you maybe be a great contributor to a data science team, or find out that you’re really awesome at one of the related sub-areas you encounter as you learn, and can have a great high-paying career doing something you love in a company that isn’t necessarily going to be “hostile to your project”?
Getting a graduate engineering degree has been harder than I anticipated (and not just because of the content), but would I go discourage someone that wants to get a similar degree? No. Would I give them advice that it’s going to be harder than they might think? Yes. And that could be stated similarly to how Deborah Siegel said in her positive response to the interview,
“What I got from the excellent advice is that data science is not a comfortable career if one want to be accepted and well-defined within a business, or if one expects clear requirements.”
But would I tell someone that if they aren’t comfortable solving convex optimization problems “right now”, they might as well avoid systems engineering graduate programs altogether? No. That would be unnecessarily discouraging, when they might later find out they excel in the degree program despite not even knowing what they’re getting into when they apply.
Though I don’t doubt that Paco Nathan has a lot of experience in the area of data science, and some of his advice is definitely valuable, his experience is not all-encompassing of all possible data science career possibilities (some of which don’t even exist yet!) to give such broad warnings about the career path as a whole. In any case, the last sentence in the section of the interview I highlighted above is way too extreme. If I took that advice to heart, I might quit now and never achieve the career I believe is a great fit for me. “If you don’t feel completely comfortable that you can handle [extreme situation] given your experience and skill set RIGHT NOW, avoid this career path!” is terrible advice to anyone starting out in any field, and put a bad taste in my mouth that overshadowed the otherwise good information.
I’m not a data scientist yet, so I could be wrong, but I have trouble listening to advice from someone that starts with a “self test” meant to scare and discourage, rather than educate and encourage, those that might have the wrong impression about Data Science, but might really end up becoming great data scientists despite any overly-dreamy first impressions.
UPDATE: Here are some of the replies/discussion from Twitter on this topic
great to read @BecomingDataSci .. no scare tactics were intended. i like your angle on this.
— paco nathan (@pacoid) April 2, 2014
Thanks @BecomingDataSci for drawing a line between being discouraged and simple reality checks @pacoid @dtunkelang
— Deborah Siegel (@dsiegel) April 2, 2014
@BecomingDataSci I imagine @pacoid wanted clarity for people claiming to be data sci because they read an article etc. it requires a lot!
— Ellen Friedman (@Ellen_Friedman) April 2, 2014
@pacoid @BecomingDataSci I think Paco’s examples were a bit over the top, but there is some truth in those scenarios
— Peter Skomoroch (@peteskomoroch) April 2, 2014
@pacoid @BecomingDataSci some of those are organizational problems for leadership roles, shouldn’t stop you from becoming a data scientist
— Peter Skomoroch (@peteskomoroch) April 2, 2014
perhaps we have common ground there.. i haven't met many orgs that weren't problematic, but still valued @peteskomoroch @BecomingDataSci
— paco nathan (@pacoid) April 2, 2014
]]>Here’s the impressive demo video:
)
And here is a link to the documentation:
http://reference.wolfram.com/language/
I don’t have a Mathematica license or Wolfram Workbench, but I could get a student copy at a discount as a graduate student. Have any of you used the Data Mining side of Mathematica before? How does this new language compare? Have you tried Wolfram Language?
h/t to Data Science 101
]]>Short Term (2014-2015):
Get an A in the graduate-level Machine Learning class I’m taking– Done. Got an A!- Finish the activities from the O’Reilly short-course, Udacity course, and Doing Data Science book (more about these later)
Complete the Codecademy Python courseDone! [review]- Learn how to use IPython and Pandas [know basics of both, more to learn!]
- Publish/share a project on GitHub
Complete a machine learning project that helps the University I work for better understand a subset of its data– Partially complete with Machine Learning class Final Project.
Update 1/7/2015: My recently-approved “capstone” project for my masters degree will fulfill this goal!
Longer Term (2014-2017):
Complete my Master’s degree in Systems Engineering (planned for Spring 2015)Done!!- Conduct a thorough study of the data at the University I work for using skills gained in my Data Science coursework to complete an analysis that can help the University raise more money during a fundraising campaign
Update 10/15/15: I have received some funding to help my department learn more about how we can apply predictive analytics and data mining as part of what we do for the university! - Become known for a University Advancement (Development/Fundraising) data science-related achievement (present my work at a CASE conference, for instance)
- Compete in a Kaggle competition or other challenge where my work is compared to others
- NEW GOAL Oct 2015: Build an awesome data science learning directory that uses data science techniques to recommend content to users to help others learn data science! Working on this at DataSciGuide.com
Long Term:
- Get to the point where I have enough skills and projects under my belt to call myself a Data Scientist (I’m aware this is quite subjective), probably with a specialty in University Advancement data
- If it seems necessary/valuable, get a Data Science certification such as the one at Cloudera
- Win a Kaggle competition
- Lead a team of Data Scientists in some way
When I was searching for a graduate degree to pursue, I knew I wanted something technical that could be applied broadly, and which tied in with my love of data, analysis, and studying how things work, without being either an IT/Database Management type program or a pure Computer Science program. Systems Engineering seemed to fit the bill because of its crossover with many fields I wanted to learn more about: computer science, artificial intelligence, cognitive science, human factors, decision theory, modeling & simulation, etc., and because I had enjoyed the introductory engineering courses I took in undergrad. The focus of the Master’s degree seemed to be “how to understand a system and make decisions about it”, which I liked, and thought would be especially applicable to a career incorporating databases in whatever industry I decided to settle into.
What I found out when I got further into the program was that this university’s version of Systems Engineering is VERY math-heavy. I had taken Linear Algebra from a community college as a prerequisite, and took graduate-level Statistics for Scientists and Engineers as part of the program, and had gotten As in both, but soon found myself in courses such as Convex Optimization which were using matrix calculus and other math I never imagined I’d be doing. (An actual Systems Engineer I talked to said that their company would never expect a Systems Engineer to perform these calculations.)
Learning this content was especially challenging because I’m in the program as a “synchronous online” student, meaning that I sit in on the classroom via the web after (or often during) work, and it is difficult to collaborate with other students or get additional help from the professors. (Luckily, my husband is a physicist, so I have an at-home tutor for those times when I get really stuck on my homework!) I started having second thoughts about whether the program was really what I wanted to do, and how it would help my career, I realized that if I wanted this degree to be useful for my life (and maintain the motivation to complete it), I’d need to focus this effort to learn advanced mathematics into something in which I was truly interested.
Around this time, I started hearing more about something called “Data Science”. I read about how Data Science was used in the Obama presidential campaign. I learned about the Netflix Prize, a contest where people built algorithms which could improve the accuracy of movie recommendations. I followed data scientists on twitter to see what it was they did and talked about. I absorbed all of the information I could about this field, and came to realize that 1) I really loved the idea of becoming a Data Scientist, and 2) it wasn’t a big stretch to mold my Systems Engineering degree to have a Data Science focus. (Also around this time, my university announced that they would be starting an MS in Data Science, but it would start as a full-time 11-month program, and not available to students in my distance-learning program, so it wasn’t an option for me.)
The more I read about the field of Data Science, the more it felt like my whole education and career path up to this point had been leading me toward it. I have some formal education in programming and statistics, along with a career in data analytics. I pride myself on having a good grasp of both the business side of data and the technical side of working with it. I was already fascinated with the possibilities surrounding the fast-growing field, and it also didn’t hurt that articles were being published showing how much money a good data scientist could make ($100K+), though that wasn’t my primary motivation. It seemed wise to steer my Systems Engineering Masters Degree to include as many Data-Science-related courses as possible, as “Data Scientist” came into focus as my dream career.
So, I signed up to take a Machine Learning course the next semester which would count as an elective toward my degree, bought some Data Science books, signed up for some online self-paced classes, and got started! I’m about a month into the Machine Learning course now, and we’re about to start our first project, so I decided to start this blog to track my activities and document the hurdles and achievements along the way. I’ll use it as a reference for myself to keep track of resources I find useful, and have a record of the projects I’ve completed. I hope it is interesting enough for others to enjoy reading, and I also hope it provides a sort of “path forward” for those interested in Becoming a Data Scientist, too!
To learn more about my “starting point” on this journey, see the “About Me” page.
I’d appreciate if you fill out a comment below telling me what brought you here, and what you look forward to reading about on this blog!
]]>